


Inside the Tech Stack Powering Modern AI Apps (From APIs to GPUs)
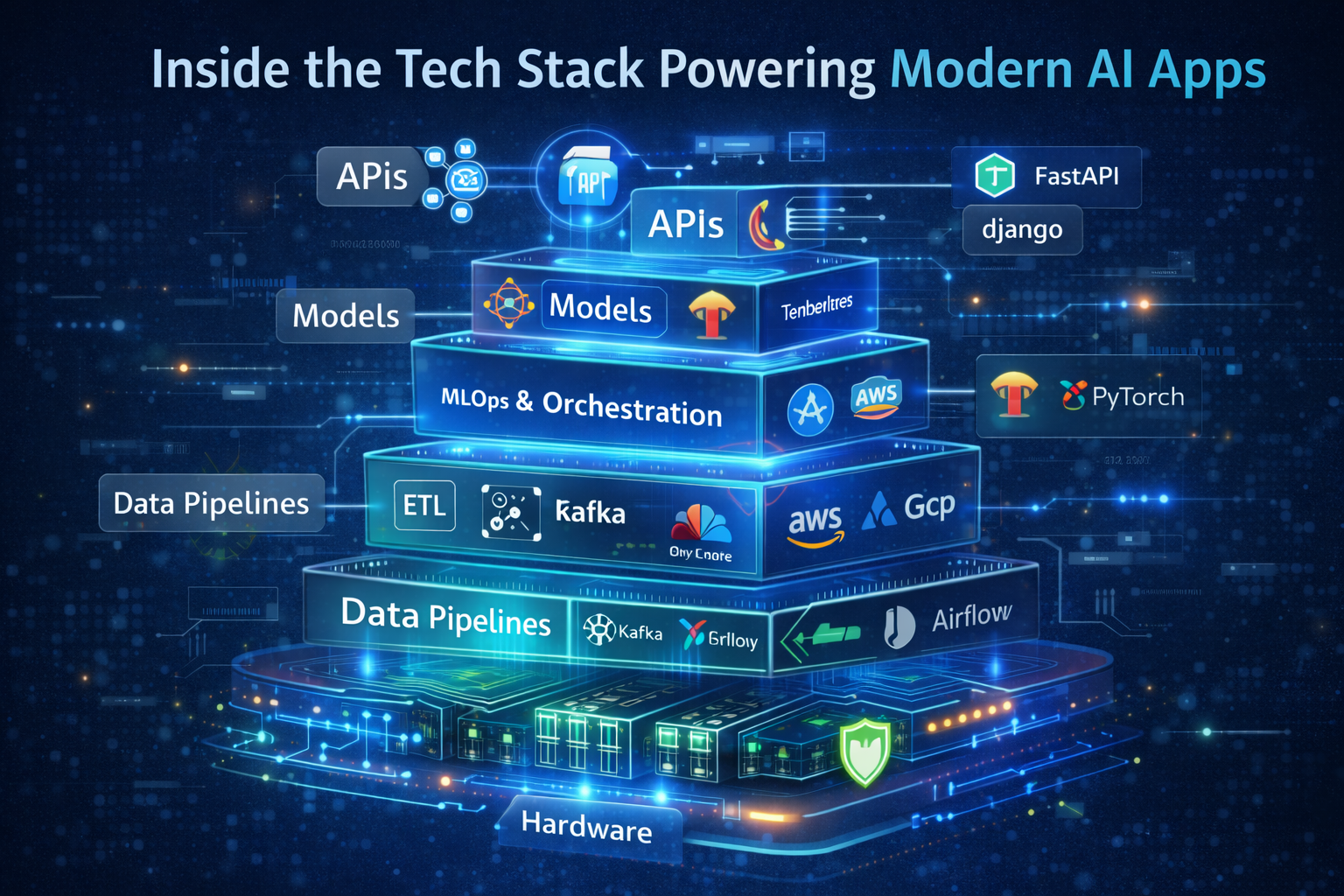
Modern AI applications aren’t powered by a single model or framework—they’re powered by a full-stack engineering ecosystem. From raw data ingestion to GPU-accelerated inference, every layer of the stack must be carefully designed for scalability, reliability, and performance (AI tech stack).
As AI systems move from demos to production-grade products, the tech stack matters more than the model itself. Let’s break down the real, commonly used technologies that power today’s AI apps—end to end.
1. Data Layer: Storage, Pipelines, and Feature Engineering 📊
Data is the foundation of every AI system. In production environments, data rarely lives in one place or one format.
Common technologies used:
- Data storage: Amazon S3, Google Cloud Storage, Azure Blob Storage
- Databases: PostgreSQL, MySQL, MongoDB, BigQuery
- Streaming & ingestion: Apache Kafka, AWS Kinesis, Apache Pulsar
- ETL / pipelines: Apache Airflow, dbt, Prefect
This layer handles data collection, cleaning, transformation, and feature extraction. Poor data engineering here leads to unreliable models, data drift, and inaccurate predictions downstream.
2. Model Development Layer: Training the Intelligence 🧠
This is where machine learning and deep learning models are built, trained, and evaluated.
Common frameworks and tools:
- ML frameworks: PyTorch, TensorFlow, JAX
- Classical ML: Scikit-learn, XGBoost, LightGBM
- NLP & CV libraries: Hugging Face Transformers, OpenCV, spaCy
Training workloads are usually split into:
- Offline training (large batch jobs)
- Online or incremental learning (for adaptive systems)
Model experimentation, hyperparameter tuning, and evaluation are often managed using tools like MLflow or Weights & Biases.
3. MLOps Layer: From Model to Production 🚦
Most AI projects fail not because of bad models, but because of poor deployment and monitoring. This is where MLOps comes in.
Key components of the MLOps stack:
- Model versioning & tracking: MLflow, Weights & Biases
- CI/CD for ML: GitHub Actions, GitLab CI, Jenkins
- Model serving: TensorFlow Serving, TorchServe, BentoML
- Monitoring & drift detection: Evidently AI, Arize, Prometheus
This layer ensures models are reproducible, auditable, and continuously improving in production.
4. API & Backend Layer: Exposing AI to Users 🔌
AI models don’t talk directly to users—APIs do. This layer connects intelligence to real-world applications.
Common backend technologies:
- API frameworks: FastAPI, Flask, Django, Express.js
- Protocols: REST, gRPC, GraphQL
- Authentication: OAuth 2.0, JWT, API gateways
This layer handles request routing, rate limiting, authentication, and response formatting. Latency optimization is critical here, especially for real-time AI applications like chatbots or recommendations.
5. Orchestration & Infrastructure Layer ☁️
To scale reliably, AI apps rely heavily on containerization and orchestration.
Widely used tools:
- Containers: Docker
- Orchestration: Kubernetes
- Cloud platforms: AWS, Google Cloud, Microsoft Azure
- Infrastructure as code: Terraform, Pulumi
This layer ensures high availability, horizontal scaling, fault tolerance, and cost optimization across environments.
6. Hardware Layer: CPUs, GPUs, and Accelerators 🚀
At the bottom of the stack lies the hardware that makes AI computationally feasible.
Common hardware used:
- GPUs: NVIDIA A100, H100, L40
- Inference accelerators: NVIDIA TensorRT, AWS Inferentia
- CPUs: Used for lightweight inference and orchestration
Training large models without GPUs is impractical. Hardware selection directly affects training speed, inference latency, and operating costs—making it a strategic decision, not just a technical one.
How These Layers Work Together 🔗
A typical AI request flow looks like this:
- User sends a request via an API
- Backend validates and routes the request
- Model inference runs on GPU-backed services
- Results are returned and logged
- Monitoring systems track performance and drift
Each layer must be optimized independently—and integrated seamlessly.
Why the AI Tech Stack Is a Competitive Advantage
In mature AI products, the stack outperforms the algorithm.
Teams that succeed in AI typically:
- Invest heavily in data engineering
- Automate training and deployment
- Optimize infrastructure costs
- Monitor models continuously
This is why two companies using the same model can see wildly different outcomes.
Final Thoughts
Modern AI apps are not just “smart”—they are engineered systems. From Kafka streams and PyTorch models to Kubernetes clusters and GPU accelerators, every layer plays a critical role – AI Tech Stack.
If models are the brain of AI,
the tech stack is the nervous system that keeps it alive ⚡
Understanding this stack isn’t optional anymore—it’s the difference between AI experiments and real-world AI products.
Also read more articles like this on Learning labs. Check out Prompt Engineering 101: How to Use AI Effectively

